
HTML5 is the most recent version of the Hypertext Markup Language – the code that describes webpages and the language that supports multimedia. It has been configured to deliver almost anything you’d want to accomplish online without requiring additional plugins or external software. Application development, animation, movies, and music are all possible using HTML5. It can also be used to build very complex applications that will run across any browsers and platforms.
HTML5 is still evolving, thus, the intricacies are hard to explain correctly. What follows is an explanation of what is possible through text-to-speech (TTS) and how it works.
TTS systems usually run in two parts: the front-end and the back-end. The former converts symbols (i.e. numbers, abbreviations) to their written-out counterparts, divides the text into sentences, and assigns phonetic transcriptions (i.e. representation of sound) to each word. The latter comes into play by converting these phonetic representations into actual sound where variations in voice pitch and talking speed can be added.
This process is the third generation of converting text to speech. The earlier generations require audio files to be recorded. Here’s an overview of the process:
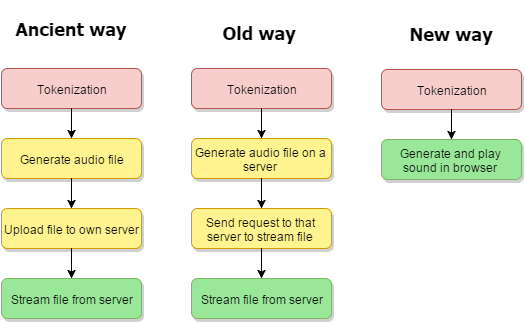
Although the practice of generating audio files is not obsolete, most speech synthesis has been successfully superseded by native speech synthesis (new process). A lot of times, these methods are combined for very specialized cases, depending on the needs and required outcomes. Native TTS is simply generating sound based on a previous analysis of a piece of text. This solution is preferred because it requires no bandwidth – there’s no need to stream the file through the internet, and saves disk/server space because no file is created and then saved. This also means that native TTS is more responsive as there is no need to wait for a file to be generated (which can take quite a bit when working with a long piece of text).
Services which create an mp3 file are only useful if you actually need the file, e.g. you want to incorporate it in a bigger audio file, or a videogame, or you want to modify it in some way. In any other case, you’ll do absolutely fine with native speech synthesis. It’s easier to set up and there’s no need to fiddle with files and FTP clients to put your audio online.
However, if you really need an audio file to be generated, here are some services available that will allow you to enter text and then download a spoken audio file. There are limitations and variations between each.
- Text2Speech (lots of languages, fairly quick to create the file),
- From text to speech (US/UK English, French, German, Italian, Spanish, Arabic),
- YAKiToMe (lots of languages, but most have a per-word cost),
- NaturalReader (only available in paid versions),
- Listen (English only).
ResponsiveVoice takes you into the future of web speech synthesis, say goodbye to managing MP3 audio files. Text to Speech is instant, there are no per-word costs and native TTS can even work without an internet connection.
Even if you have to use MP3s today, we hope this article has opened your ears to what is possible for your future projects and businesses. Try ResponsiveVoice now!
